;){kind=link}
大招憋出来了!OpenAI发布最强推理模型o1,它真的会思考,但API比4o贵好几倍
OpenAI 的推理模型,也就是期待已久的 Strawberry 发布!
9 月 13 日凌晨,OpenAI 宣布,正式发布一款 OpenAI o1-preview 的推理模型,同时发布的还有一个更小、成本更低的版本——o1 mini。
OpenAI 将此次发布称为「预览版」,强调 o1 仍处于早期阶段。
OpenAI 的 API 负责人发文称:「如果你过去有个产品想法,当时的模型不太行,不够智能,现在你再试试」。
在权限开放方面,OpenAI 采取了分阶段推广策略。
ChatGPT Plus 和 Team 用户可以立即访问 o1-preview 和 o1-mini。
Enterprise 和 Edu 用户将在下周获得访问权。
API 使用等级 5(已消费 1,000 美元且自首次付款以来已超过 30 天)的开发者,今日起可使用这两款模型,速率限制为 20 RPM。
OpenAI 还计划在未来向所有 ChatGPT 的免费用户开放 o1-mini 的使用权。
对于开发者而言,通过 API 使用 o1 的成本不便宜。o1-preview 的定价为每百万输入 token 15 美元,每百万输出 token 60 美元,远高于 GPT-4o 的定价(输入 5 美元/百万 token,输出 15 美元/百万 token)。
01
OpenAI 员工:
o1 重新定义了游戏规则
在 OpenAI 员工的推文中,可以看到他们对于 o1 能力的赞许,以及一些关键的能力升级要点。
OpenAI API 负责人 Michelle Pokrass 推文:
o1-preview 和 o1-mini 模型已经上线。它们是我们目前为止在推理方面表现最佳的模型,我们相信它们将为 API 解锁全新的应用场景。
如果你有一个产品创意,但时机尚未成熟,模型还不够智能——不妨再次尝试。
这些新模型并不能完全替代 4o。
你需要以不同的方式进行提示,并以新的方式构建你的应用程序,但我们认为它们将有助于缩小智能差距,帮助你开发出更好的产品。
(现在为 API 第五级用户推出,用户也将很快可以使用)

Greg Brockman 的推文:
OpenAI o1—我们第一个通过强化学习训练的模型,在回答问题之前会深入思考。团队的工作令人非常自豪!
这是一个充满巨大机遇的新范式。这一点在定量上(例如推理指标已经显著提升)和定性上(例如忠实的思维链使模型易于理解,因为它允许你以简单的英语「阅读模型的思维」)都很明显。
可以这样理解,我们的模型进行系统 I 思考,而思维链则解锁了系统 II 思考。人们已经发现,提示模型「一步步思考」可以提升性能。但是通过试错来训练模型,从头到尾这样做,则更为可靠,并且——正如我们在围棋或 Dota 等游戏中所见——可以产生极其令人印象深刻的结果。
o1 技术仍处于早期阶段。它提供了新的安全机会,我们正在积极探索,包括可靠性、幻觉和对抗攻击者的鲁棒性。例如,我们已经看到,通过思维链让模型推理策略,我们的安全指标有了很大的提升。
其准确性也有很大的改进空间——例如,从我们的发布帖子来看,我们的模型在今年的编程奥林匹克竞赛(IOI)中,在人类条件下(每个问题 50 次提交)取得了第 49 百分位/213 分。但是,如果允许模型问题提交 10000 次,模型取得了 32.14 分——超过了金牌门槛。因此,模型能够产生比最初看起来更大的输出。
OpenAI 研究员 Jason Wei 的推文:
o1 是一个在给出最终答案之前会进行思考的模型。用我自己的话来描述,以下是对人工智能领域最大的更新:
不要仅仅通过提示来执行思维链,而是使用强化学习训练模型以更好地进行思维链。
在深度学习的历史中,我们一直试图扩展训练计算,但思维链是一种自适应计算,也可以在推理时进行扩展。
AIME 和 GPQA 的结果非常强大,但这并不一定转化为用户可以感受到的东西。即使是工作的人,也很难找到 GPT-4o 失败、o1 表现良好并且我可以评分的提示切片。但当你找到这样的提示时,o1 感觉完全像魔法一样。我们都需要找到更难的提示。
使用人类语言进行思维链的 AI 模型在很多方面都很棒。模型做了很多类似人类的事情,比如将棘手的步骤分解为更简单的步骤,识别和纠正错误,以及尝试不同的方法。强烈鼓励每个人都去看看博客文章中的思维链例子。
游戏规则已经完全被重新定义了。
02
AI 能力的新飞跃,
所以取名 o1
o1 采用强化学习技术进行训练,专门设计用于处理复杂的推理任务。与传统模型不同,o1 具有"深思熟虑"的能力——在给出最终回答之前,它能够在内部进行长链条的逻辑推理和思考过程,从而确保回应的质量和深度。
通过精心设计的训练过程,这些模型不仅学会了如何优化思考过程,还能灵活运用不同的问题解决策略,并且具备自我纠错的能力。
测试结果令人振奋。在即将推出的模型更新中,它在物理、化学和生物学等领域的复杂基准测试中,表现堪比博士生水平。
特别值得一提的是,它在数学和编程方面的表现尤为出色。举例来说,在国际数学奥林匹克(IMO)的资格考试中,我们的新推理模型正确解答了 83% 的问题,远超 GPT-4o 的 13%。在编程能力方面,通过 Codeforces 竞赛的评估,新模型的表现超过了 89% 的参赛者。
作为一个处于早期阶段的模型,它目前还不具备 ChatGPT 的一些实用功能,如网络浏览、文件上传和图像处理等,它在世界事实知识方面的表现也不如后者。短期内,对于日常应用场景,GPT-4o 可能仍然更为实用。
然而,在复杂推理任务方面,这个新模型代表了 AI 能力的一个重大飞跃。基于这一突破性进展,我们决定将计数器重置为 1,并将这个全新的模型系列命名为 OpenAI o1,以彰显其开创性意义。
我们开发了一种创新的大规模强化学习算法,这种算法能够在高效利用数据的同时,有效地训练模型运用其思维链进行富有成效的推理。这种训练方法的核心在于教会模型"如何思考",而不仅仅是存储和检索信息。
通过持续的研究,我们发现了两个关键因素能显著提升 o1 模型的性能:
增加强化学习的计算量(即训练阶段的计算资源投入)
延长模型的"思考时间"(即在测试或应用阶段给予模型更多的计算时间)
这种方法在扩展性方面表现出了与传统大语言模型预训练截然不同的特点。传统的预训练主要受限于海量文本数据的获取和处理,而我们的方法更多地依赖于计算资源和算法优化。目前,我们正深入研究这种新方法的扩展限制,以期在未来取得更大的突破。
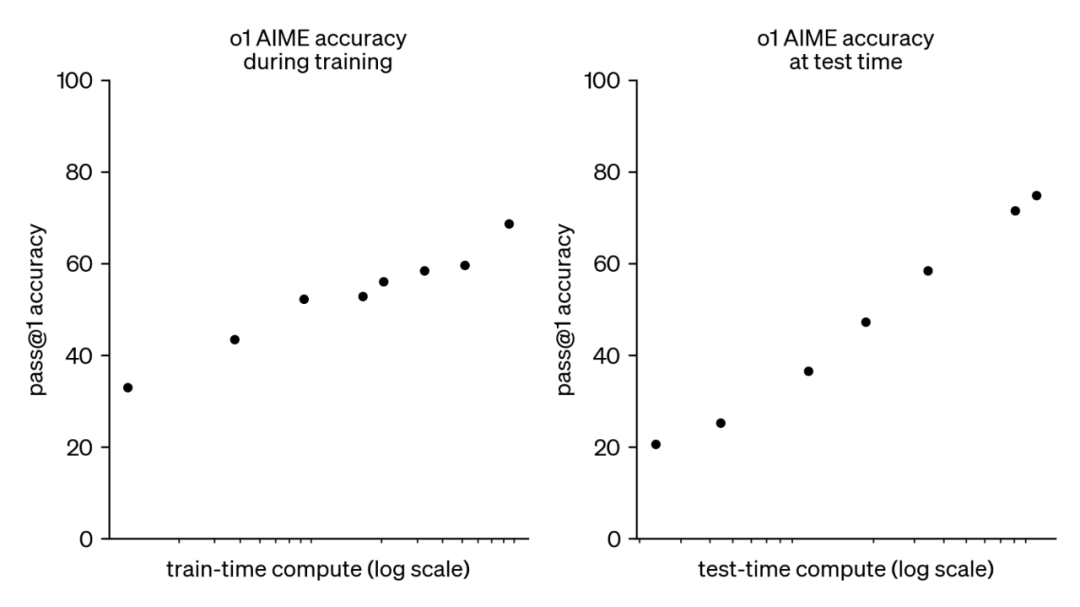
o1 的性能随着训练时计算和测试时计算的增加而平稳提升。
03
数学:全面碾压 4o,
成绩跻身全美前 500 名之列
为了凸显 o1 模型在推理能力上相比 GPT-4o 的显著进步,我们设计了一套全面而严格的评估方案。这个方案包括了各种人类专业考试和机器学习领域公认的基准测试,涵盖了广泛的知识领域和复杂的推理任务。
测试结果令人振奋:在绝大多数需要深度思考和复杂推理的任务中,o1 模型都展现出了明显优于 GPT-4o 的表现。这一结果有力地证明了 o1 在处理高难度、需要多步推理的问题时的卓越能力。
值得注意的是,除非我们特别说明,所有针对 o1 的评估都是在最大化测试时间计算资源的情况下进行的。这意味着我们充分发挥了 o1 模型的潜力,让它有足够的"思考时间"来处理这些复杂任务。
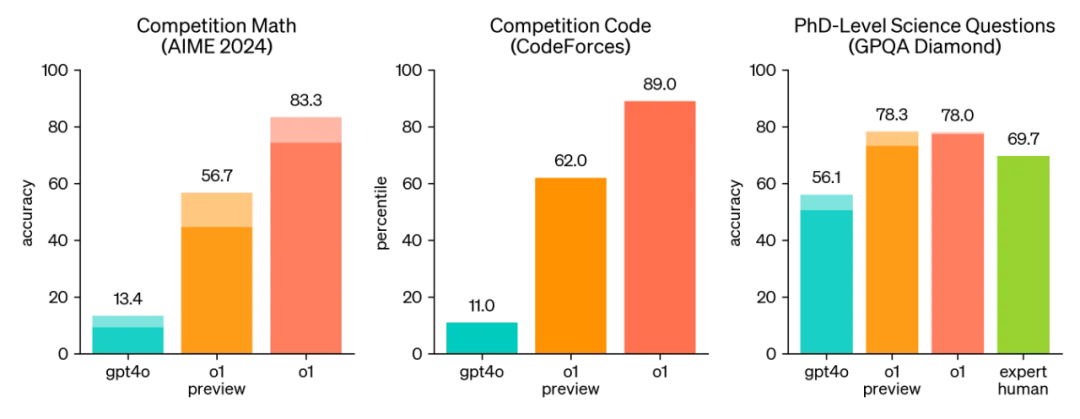
o1 在具有挑战性的推理基准测试中显著优于 GPT-4o。实心条表示 pass@1 准确率,阴影区域显示 64 个样本的多数投票(共识)性能。
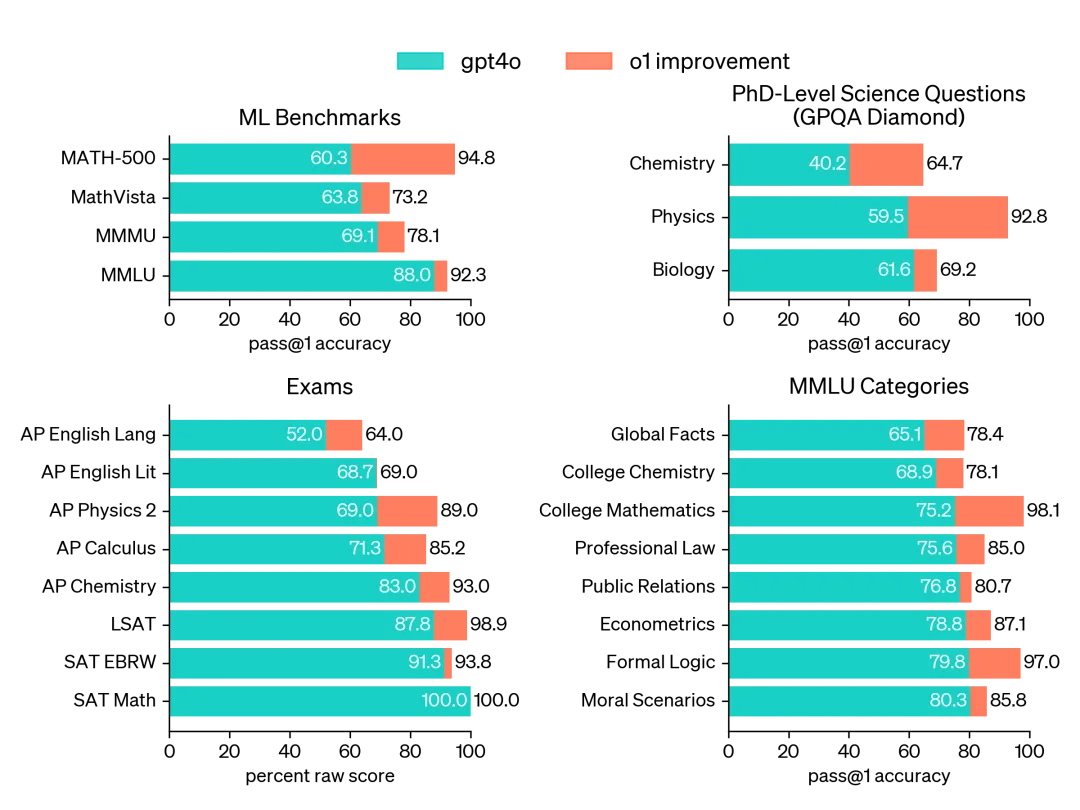
o1 在广泛的基准测试中超越了 GPT-4o,涵盖了 57 个 MMLU 子类别中的 54 个。
o1模型在复杂推理领域的卓越表现,犹如一颗璀璨的明星,在众多基准测试中熠熠生辉,其能力之强,已可与人类专家平分秋色,实乃非凡成就。尤为值得注意的是,当传统数学测试如MATH2和GSM8K对于顶尖AI模型而言变得轻而易举,o1却选择了更为险峻的道路——挑战美国数学邀请赛(AIME),这一专为精英高中生设计的学术高峰。
在2024年的AIME战场上,o1与GPT-4o的较量结果令人瞩目。GPT-4o虽强,却仅能在题海中触及皮毛,平均解题率仅为12%。而o1,则如同破晓之光,单次尝试便解锁了74%的难题,经过64次采样的智慧汇聚,更是将正确率推升至83%。更令人惊叹的是,当采样次数达到1000次,并辅以学习型评分函数的精心筛选后,o1的解题正确率竟飙升至93%,相当于在AIME中斩获了13.9分的高分,这一成绩足以让o1跻身全美前500名高中生的行列,甚至超越了美国数学奥林匹克竞赛的选拔门槛。
不仅如此,o1在GPQA diamond测试中的表现更是石破天惊,它首次跨越了人类与AI之间的界限,以超越博士级专家的卓越表现,成为该基准测试中的新王者。这一壮举不仅彰显了o1在特定专业领域知识的深度与广度,更预示了AI在复杂知识任务中的无限潜力。
然而,荣耀背后,我们应保持谦逊与审慎。o1的超越并不意味着它在所有领域都能全面压制人类专家,而是表明在特定任务上,AI能以惊人的效率与精准度展现其独特优势。
此外,o1在MMMU与MMLU等多模态与多任务基准测试中的卓越表现,更是为其能力图谱添上了浓墨重彩的一笔。它不仅在视觉感知与多模态理解上达到了人类水平,更在广泛的知识领域与任务类型中展现了全面领先的实力。这些成就不仅推动了AI技术的边界,更为未来AI在更多复杂场景中的应用铺设了坚实的道路。
总而言之,o1模型以其卓越的推理能力、深度的专业知识以及广泛的任务适应性,正逐步揭开AI通用智能与专业领域应用的新篇章。
04
编程:编程竞赛优于 93% 的参赛者
经过对o1模型的深度优化与专项编程训练,我们成功孕育出一个在编程领域独领风骚的AI新星。在2024年国际信息学奥林匹克竞赛(IOI)的激烈角逐中,该模型以惊人的213分高分脱颖而出,跻身顶尖参赛者行列的前50%,这一壮举深刻揭示了AI在解决高难度编程任务上的巨大潜力。
竞赛环境与挑战概览:
公平竞技:AI与人类选手在完全相同的竞赛环境中一决高下。
严苛挑战:10小时内需攻克6道算法难题,每题限50次提交,考验着解题速度与精准度。
创新策略引领胜利之路:
我们独创了一套高效的测试时选择策略,通过“多样化采样”生成海量候选解,再经“智能筛选”机制,结合公开测试案例、自生成案例及定制评分函数,精准挑选出50个最优解进行提交。此策略实施后,模型成绩飙升近60分,彰显了其在高压竞赛中的非凡竞争力。
突破极限,展现无限可能:
当提交次数限制放宽至每题10,000次时,模型更是以362.14分的惊人成绩轻松跨越金牌门槛,预示着其在更宽松条件下的无限潜能。
Codeforces平台上的辉煌战绩:
在Codeforces这一编程竞技的模拟战场上,我们的AI模型同样大放异彩。遵循严格比赛规则,每题仅10次提交机会下,模型荣获1807 Elo评分,将93%的人类选手甩在身后。与GPT-4o的808 Elo评分(仅超越11%人类)相比,我们的模型实现了质的飞跃,不仅远超GPT-4o,也大幅刷新了o1的既有记录。
综上所述,这一系列卓越表现不仅标志着AI在编程领域的重大突破,更预示着未来AI与人类在智力竞技场上将展开更多元、更深层次的对话与合作。
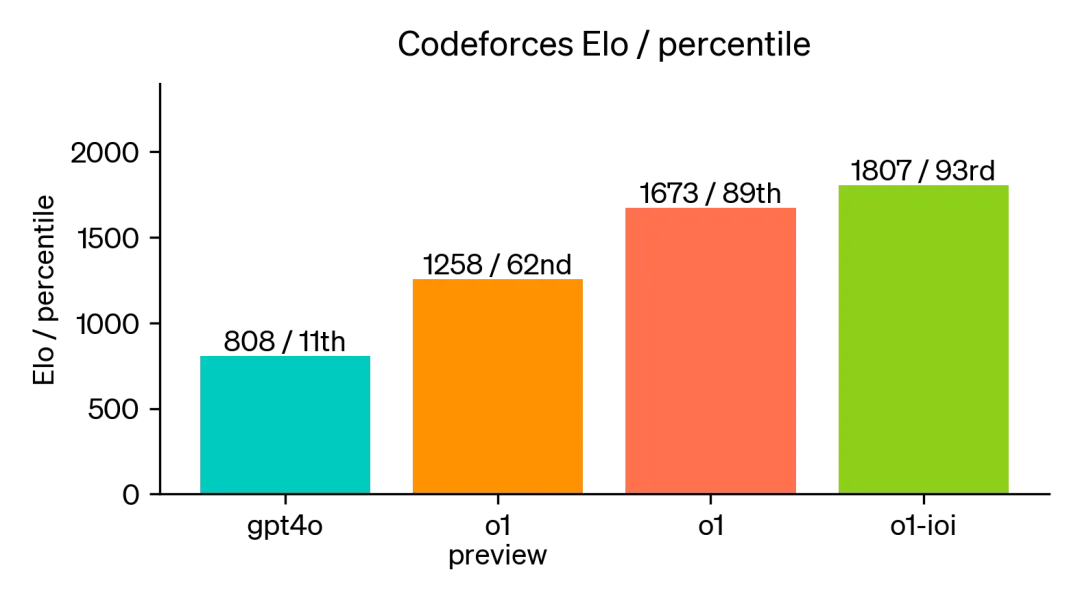
通过在编程竞赛上进一步微调改进了 o1。在竞赛规则下,改进后的模型在 2024 年国际信息学奥林匹克竞赛中排名在第 49 百分位。
05
人类偏好评估:
文本生成 4o 仍占优势
为了全面评估 AI 模型的实际应用效果,我们不仅关注传统的考试成绩和学术基准,还进行了一项创新的人类偏好评估。这项评估旨在比较 o1-preview 和 GPT-4o 两个模型在处理各种领域复杂、开放性问题时的表现。
评估方法:
范围广泛:涵盖了多个不同领域的挑战性问题。
开放式提示:使用开放性问题来测试模型的灵活性和创造力。
匿名对比:向人类评估者展示两个模型的匿名回答。
人工判断:由经过培训的人类专家投票选择他们认为更优秀的回答。
关键发现:
o1-preview 的优势领域:
在需要深度推理能力的领域中,o1-preview 表现出色,大幅领先于 GPT-4o。
这些领域主要包括:数据分析、编程和数学。
优势明显,显示出 o1-preview 在处理复杂逻辑和抽象思维方面的卓越能力。
GPT-4o 的优势领域:
在某些自然语言处理任务中,GPT-4o 仍然保持优势。
这表明语言模型在处理日常交流、文本生成等任务时可能更有优势。
模型适用性的差异:
o1-preview 虽然在某些领域表现出色,但并非全能。
这一发现强调了不同 AI 模型在不同任务中的专长,暗示了未来 AI 应用可能需要任务特定的模型选择。
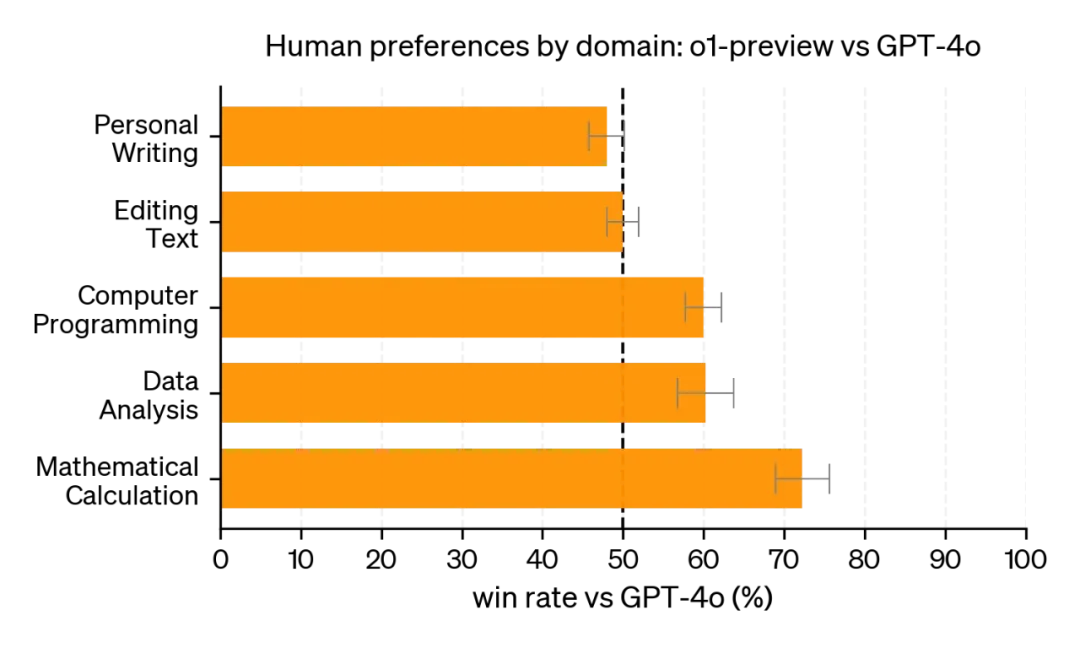
结论:这项评估不仅展示了 o1-preview 在处理复杂推理任务时的优越性,也揭示了 AI 模型能力的多样性。它提醒我们,在选择和应用 AI 模型时,需要根据具体任务和场景来选择最合适的工具。同时,这也为未来 AI 模型的开发提供了方向,即如何在保持强大推理能力的同时,提升在自然语言处理等领域的表现。
06
幻觉没有解决,
但思维链很强大
在AI的前沿探索中,“思维链”这一概念如同璀璨星辰,引领着o1模型在复杂任务处理上的新纪元。它不仅仅是AI内部推理过程的可视化展现,更是对人类智慧运作机制的一次深刻模拟。通过这一机制,o1如同拥有了一串逻辑严密的珍珠项链,每一颗珍珠都代表着从疑惑到解答的精心雕琢。
o1的学习之旅,是一场对“思维链”艺术的不懈追求。强化学习如同一位严苛的导师,不断鞭策着o1优化其内部的推理路径,让每一条思维链都更加坚韧、高效。在这个过程中,o1学会了自我审视,能够敏锐地捕捉并修正推理中的谬误,确保每一步都坚实可靠。
更令人赞叹的是,o1还展现出了卓越的问题拆解能力。面对庞杂难解的问题,它如同一位策略大师,将难题化繁为简,逐一击破。这种能力不仅提升了解决问题的效率,更让o1在面对未知挑战时能够游刃有余。
而最令人瞩目的,莫过于o1那灵活多变的方法转换策略。当既定路径遭遇阻碍,o1不会固步自封,而是勇于探索新的可能性,寻找更为有效的解决方案。这种不拘一格的创新精神,正是AI智慧与人类智慧相契合的生动体现。
综上所述,o1的学习过程是一场对“思维链”艺术的深度挖掘与升华。它不仅在技术上实现了对复杂问题的精准处理,更在哲学层面上展现出了AI对智慧本质的深刻理解和不懈追求。通过这一过程,o1正逐步构建起一座连接人类智慧与AI智能的桥梁,让未来的世界因AI而更加精彩纷呈。
在句意转换的视角下,这段描述不仅保留了原文的核心信息,还通过更加生动、形象的语言表达,让读者能够更加直观地感受到o1学习过程的魅力与深度。
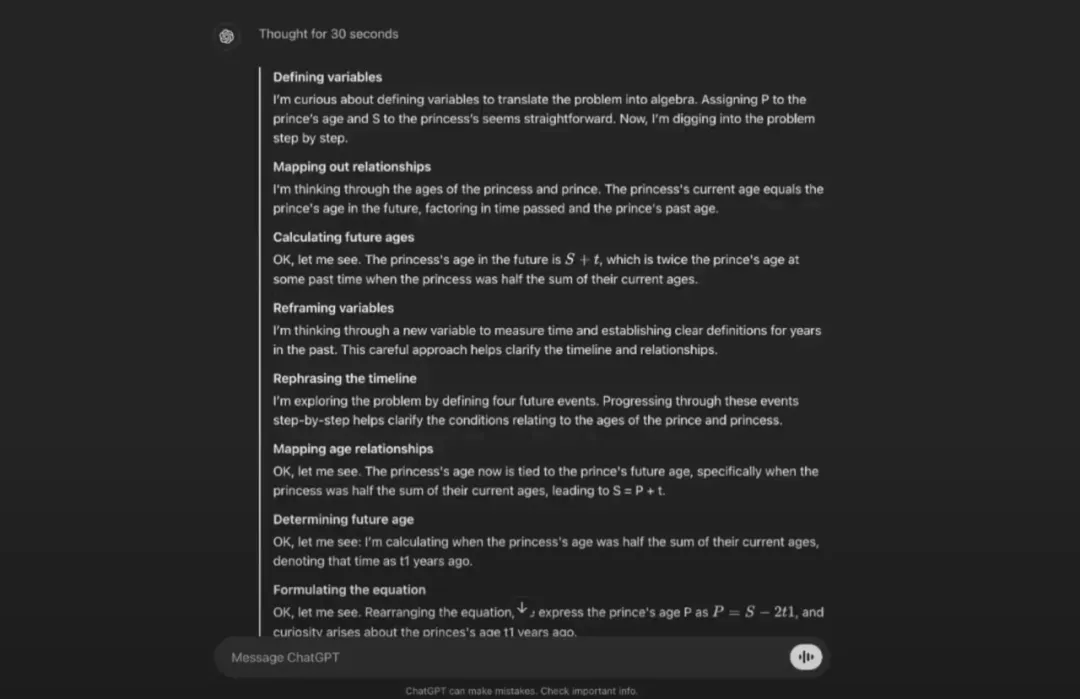
诸如「我对……感到好奇」、「我正在思考」和「好的,让我看看」这样的短语,呈现一种思考的感觉。
在探讨思维链的潜在价值及其展示方式的考量中,我们确实需要在保持技术深度与提升用户体验之间找到一个平衡点。您所提到的措施——智能提取和摘要生成,以及我补充的句意转换策略,都是实现这一目标的有效手段。
智能提取
智能提取技术能够自动分析复杂的思维链,识别出对于用户理解或决策最为关键的信息点。这一过程不仅要求模型具备强大的信息处理能力,还需要深入理解问题背景和用户需求,以确保提取的信息既准确又相关。通过智能提取,我们可以将冗长、复杂的思维链简化为精炼、易懂的要点,直接融入最终回答中,提升用户体验。
摘要生成
摘要生成是对智能提取的进一步升华,它不仅仅提取关键信息,还通过自然语言处理技术将这些信息重新组织成连贯、流畅的文本。对于o1模型系列,提供由模型生成的思维链摘要,不仅能够保留思维链中的核心逻辑和推理步骤,还能以更加用户友好的方式呈现,帮助用户快速把握AI的决策依据。
句意转换
句意转换技术则更进一步,它不仅仅是对信息的重新组织,还涉及到对语言风格的调整和优化。通过句意转换,我们可以将原始思维链中可能存在的专业术语、复杂句式转换为更加通俗易懂的语言,同时保持原意的准确性。这样,即使不直接展示原始思维链,用户也能通过转换后的句子感受到AI决策背后的逻辑和推理过程,从而增加对AI的信任度。
综上所述,智能提取、摘要生成以及句意转换这三种策略相辅相成,共同构成了在隐藏思维链的同时提供有价值信息的有效方案。它们不仅提升了用户体验,还保护了核心技术细节,为AI的透明度和可信度奠定了坚实的基础。
07
o1 最适合哪些领域
模型凭借其卓越的推理能力,正逐步成为多领域专业人士不可或缺的助力,尤其是在科学研究、软件开发及数学计算的浩瀚挑战中,其影响尤为显著。具体而言,该模型在以下领域展现了非凡的应用潜力:
医疗科研前沿:生物信息学专家可依托o1,在细胞测序数据的繁琐注释工作中找到高效捷径,极大加速了基因组研究的步伐。
物理学探索新纪元:在量子光学等物理学尖端领域,物理学家能够借助o1生成复杂精妙的数学表达式,为理论研究的深化与实验设计的优化插上翅膀。
软件开发的智能化革命:跨越行业的开发者们均可利用o1构建并执行繁琐的多步骤工作流程,将复杂的编程任务化繁为简,显著提升开发效率与质量。
综上所述,o1模型作为一款强大的智能辅助工具,正深刻改变着那些致力于解决高度复杂问题、开展深度分析及创新研究的专业人士的工作方式,为他们开启了一个全新的智能支持时代。