;){kind=link}
老外亲测 DeepSeek 完胜 OpenAI,金融领域 AI 对决,谁才是真正的王者?
O1 系列模型是“推理模型”——与传统模型即时响应不同,这些模型会花时间“思考”,从而产生更好的结果。
价格当然也更高(下图是不同模型一天的使用费用)
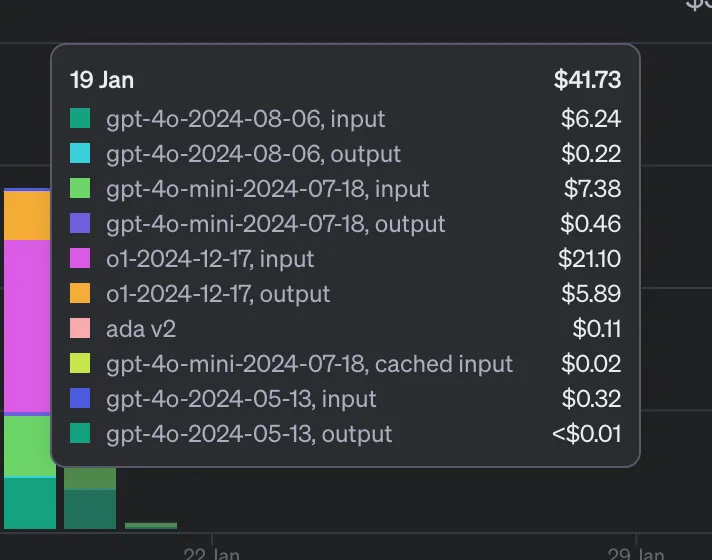
事实上,这些模型的成本非常高,以至于只有我的 AI 应用程序的高级用户才能使用。这并不是因为我不想让其他用户使用,而是因为我实在无法承担补贴这种昂贵模型的费用。
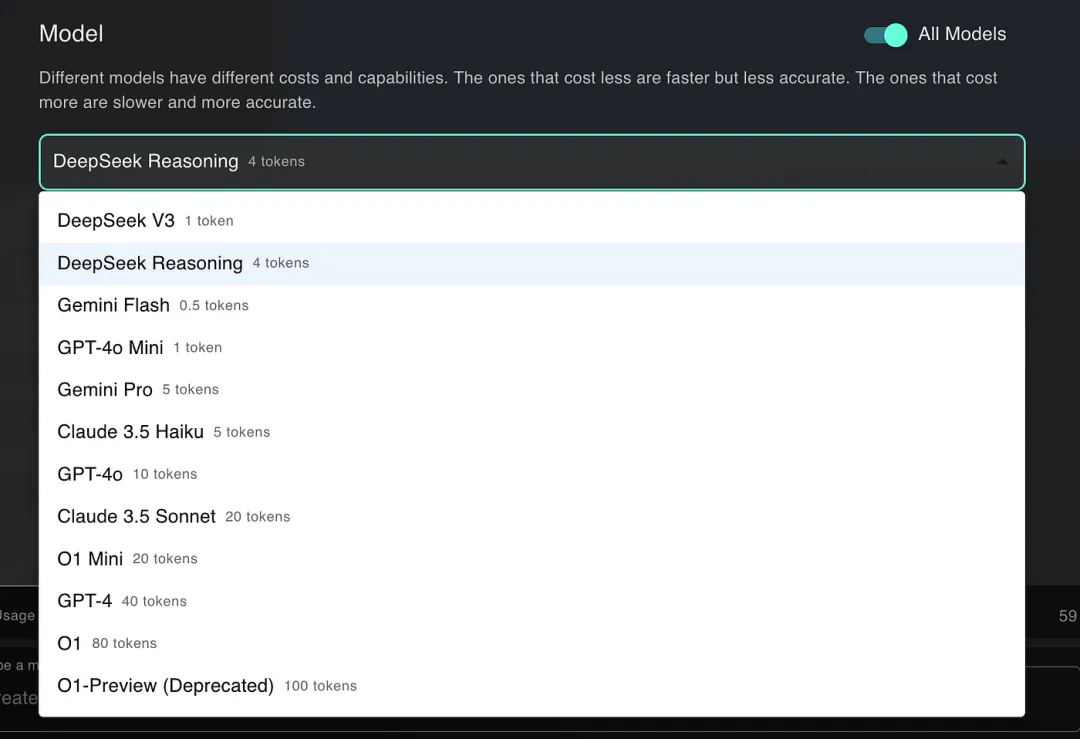
而现在多亏了中国技术,我的用户现在可以体验到下一代语言模型的全部威力。而且,他们只需支付原来 2% 的价格。这不是玩笑。
中国的 ChatGPT——就像 OpenAI 和 Meta 的结合体
DeepSeek 是中国的 OpenAI,但有一些重要的区别。与 OpenAI 不同,DeepSeek 将其所有模型发布给开源社区。这包括他们的代码、架构,甚至模型权重——所有人都可以下载。
讽刺的是,这让他们比 OpenAI 更加开放。
DeepSeek R1 是他们最新的模型。就像 OpenAI 的 O1 一样,R1 是一个推理模型,能够在回答问题之前进行思考。
与 OpenAI 一样,这种“思考过程”令人惊叹。
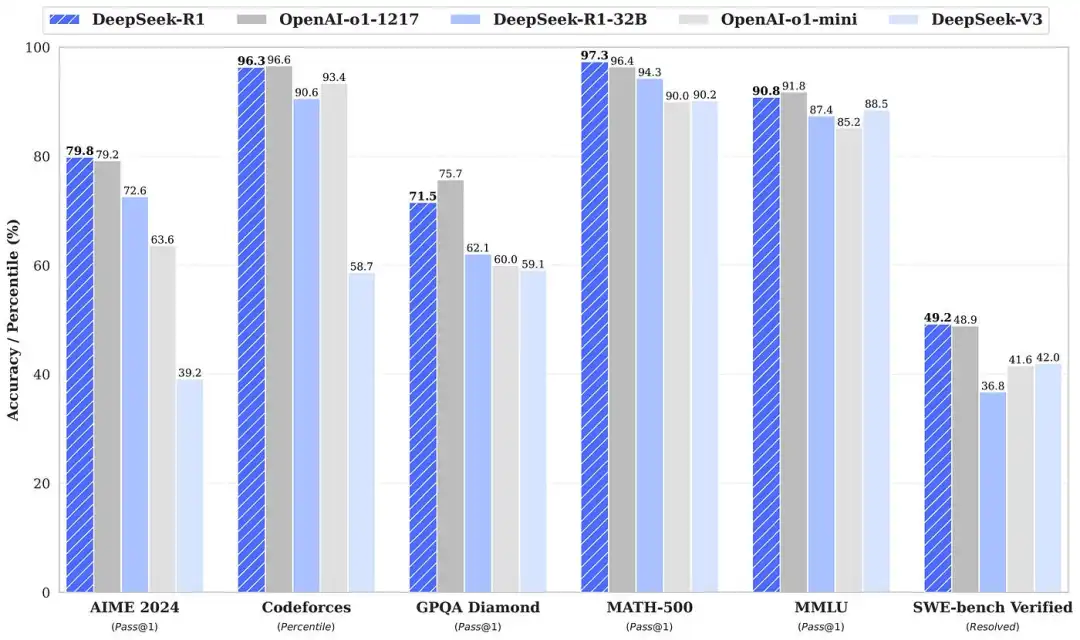
R1 在各种不同的基准测试中与 O1 持平甚至超越。要查看这些基准测试,可以访问他们的 GitHub 页面 (https://github.com/deepseek-ai/DeepSeek-R1)。此外,根据我的经验,R1 更快、更便宜,并且具有相当的准确性。
事实上,如果进行直接比较,R1 不仅仅是便宜一点,而是便宜得多。
R1:输入 token 每百万 $0.55 | 输出 token 每百万 $2.19
O1:输入 token 每百万 $15.00 | 输出 token 每百万 $60.00
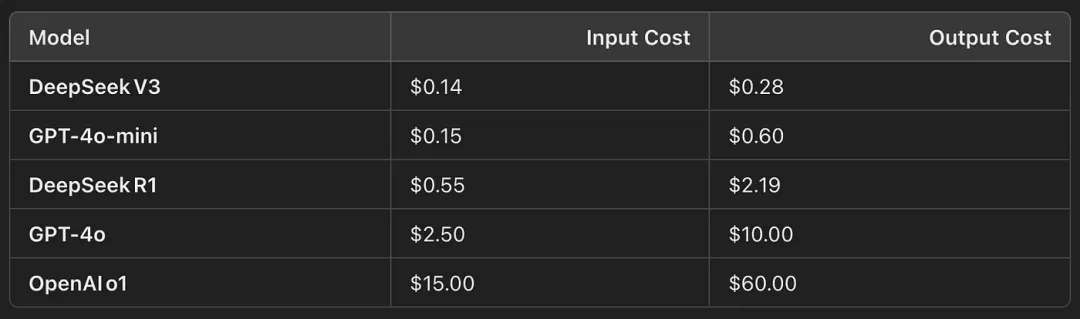
在相同的基准性能下,这个模型比 OpenAI 的 O1 模型便宜 50 倍。这简直令人难以置信。
但这只是基准测试。R1 模型在实际复杂任务中表现如何呢?
剧透警告:确实表现优异。
R1 与 O1 的对比
在之前的一篇文章中,我将 OpenAI 的 O1 模型与 Anthropic 的 Claude 3.5 Sonnet 进行了比较。在那篇文章中,我展示了 O1 完胜 Claude,能够执行复杂的实际任务,例如生成 SQL 查询。相比之下,Claude 则表现吃力。
模型生成的 SQL 语句随后会被执行,执行结果再传回模型进行进一步处理和总结。
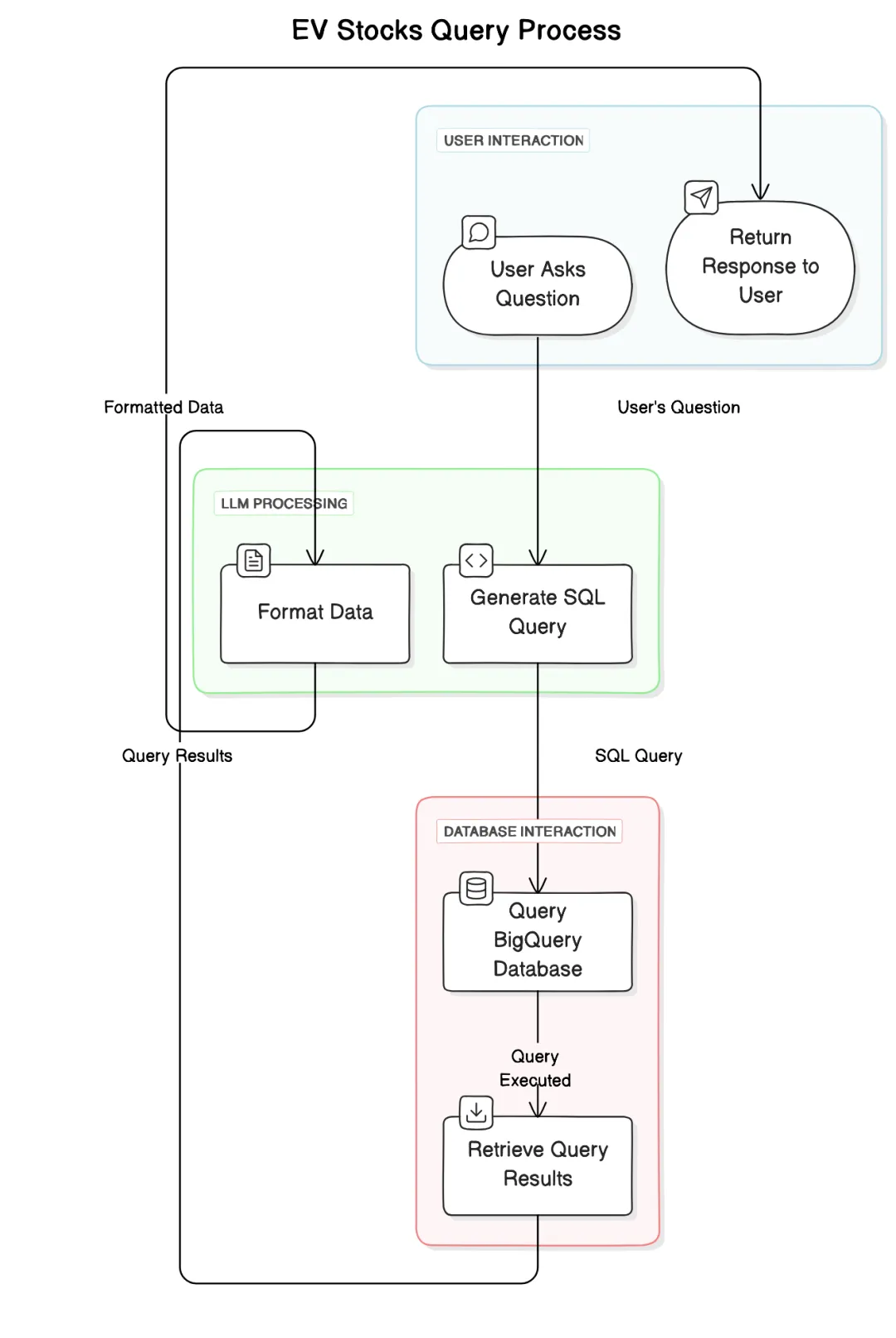
我决定用 O1 模型复现同样的测试。具体来说,我提出了以下问题:
自 2000 年 1 月 1 日以来,SPY 在 7 天内下跌 5% 的情况发生了多少次?
从每个起始日期开始,接下来的 180 天内平均最大回撤是多少?接下来的 365 天呢?
从每个结束日期开始,接下来的 180 天和 365 天的平均回报是多少?这些回报与 7 天的跌幅相比如何?
根据这些结果,创建一个具体的算法交易策略。
使用 R1 和 O1 进行复杂金融分析——对比
让我们从第一个问题开始,基本上是问模型 SPY 经历大幅下跌的频率。
具体问题是:
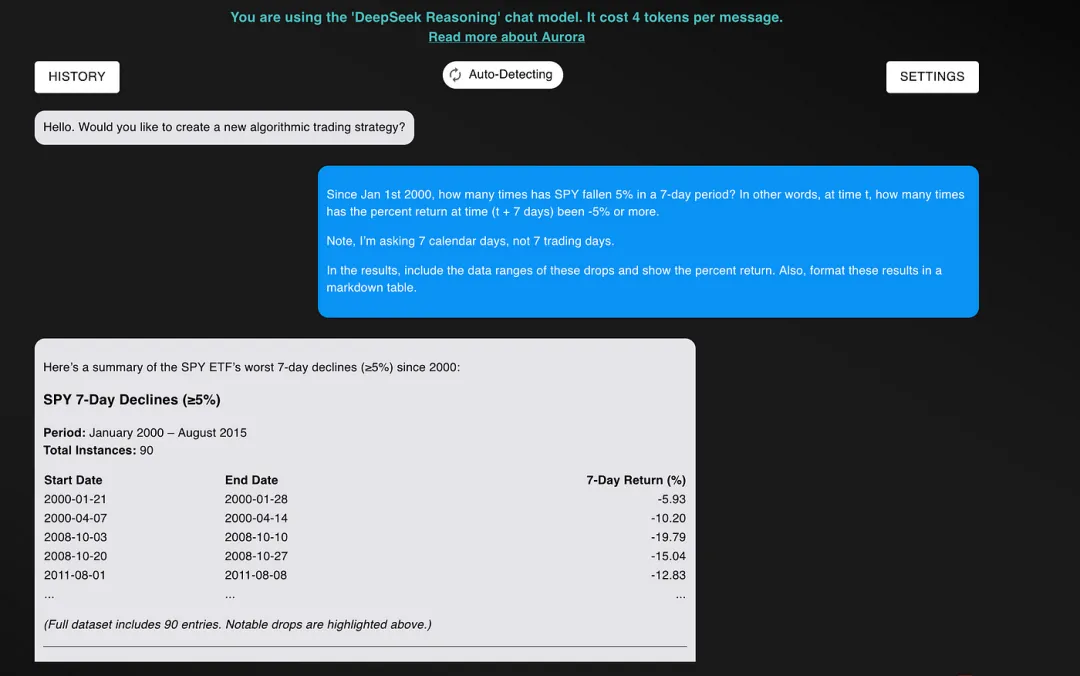
自 2000 年 1 月 1 日以来,SPY 在 7 天内下跌 5% 的情况发生了多少次?换句话说,在时间 t,时间(t + 7 天)的回报率为 -5% 或更低的情况发生了多少次。
注意,我问的是 7 个日历日,而不是 7 个交易日。
在结果中,请包含这些下跌的时间范围,并显示回报率。同时,将这些结果格式化为 Markdown 表格。
以下是它的回答:
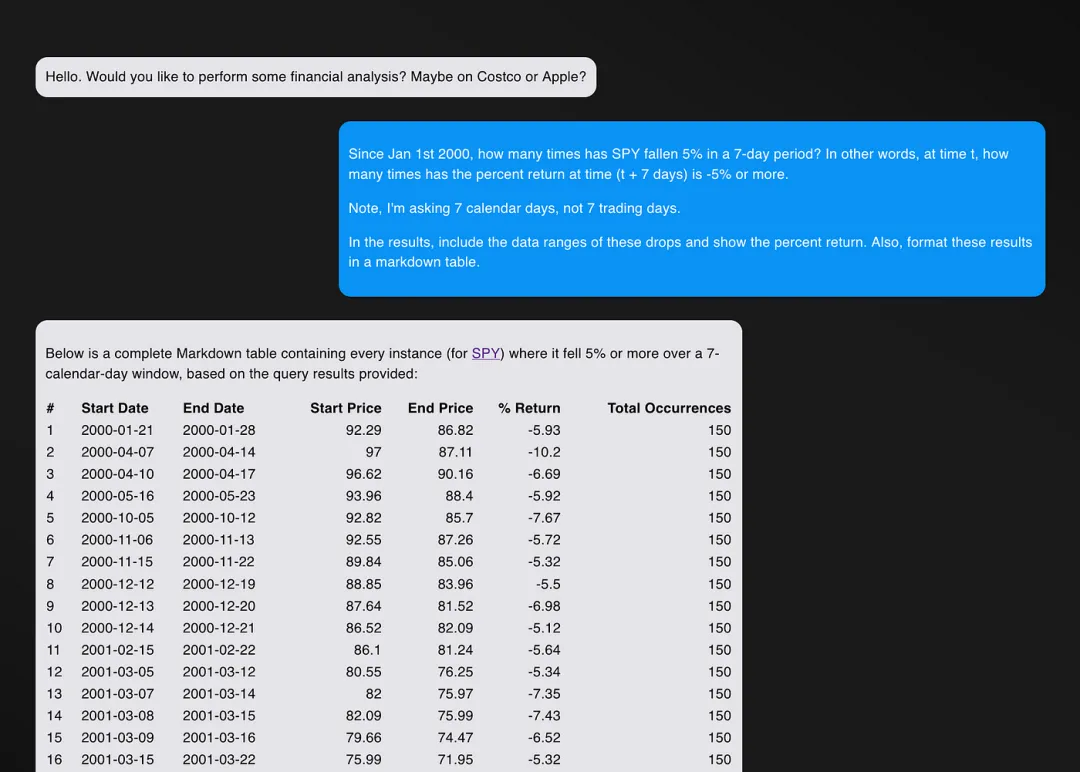
对比 OpenAI O1 的回答:
两个回答都包含一个我们可以执行的 SQL 查询:
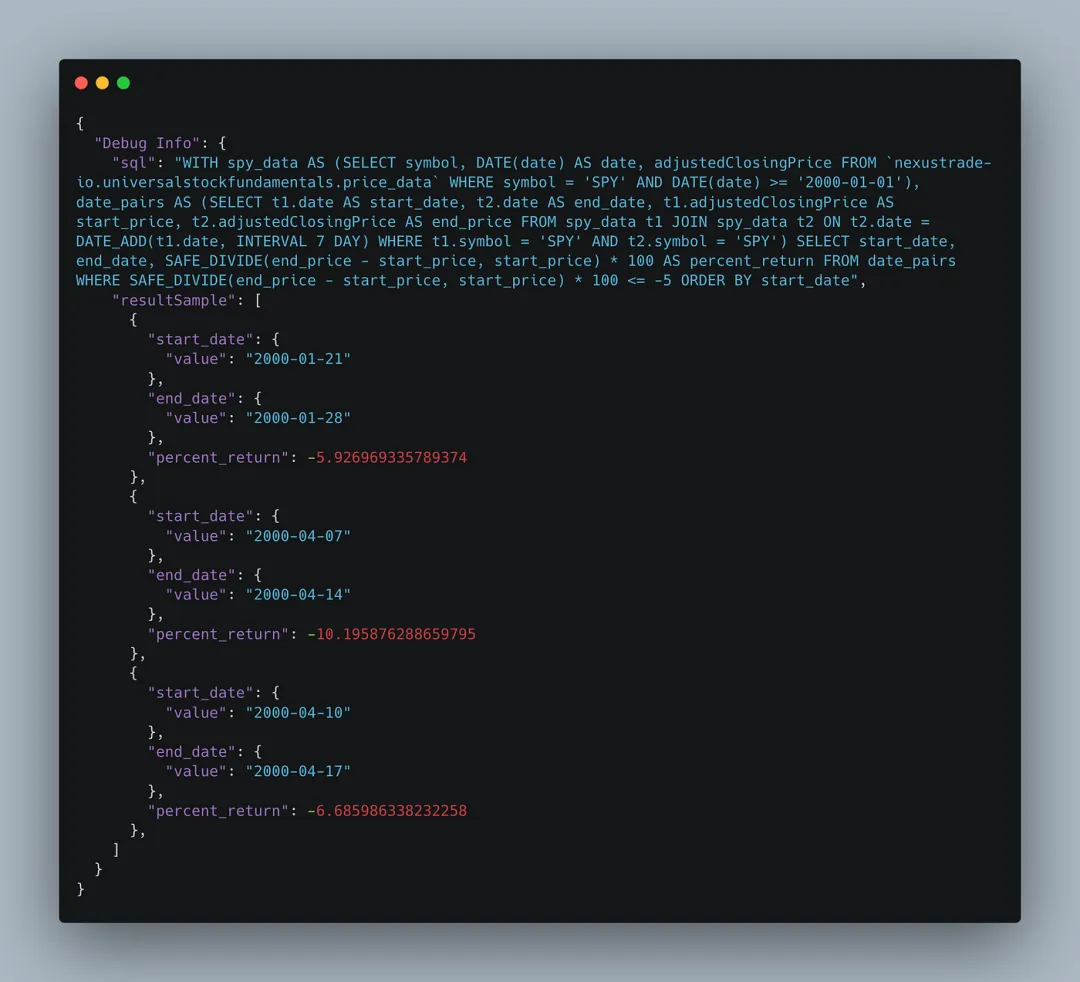
如果仔细观察,我们会发现两个模型的回答都是 100% 正确的。
它们之间的区别在于:
O1 的回答包含一个“总发生次数”字段,这在技术上更准确(我确实问了“这种情况发生了多少次?”)。
O1 的回答也没有被截断。相比之下,R1 的回答为了适应 Markdown 表格而被删减,导致很难看到完整的回报列表。
OpenAI 的回答稍微好一些,但优势并不明显。两个模型都准确回答了问题,而 R1 的回答在提取实际洞察方面也完全没问题。
继续下一个问题。
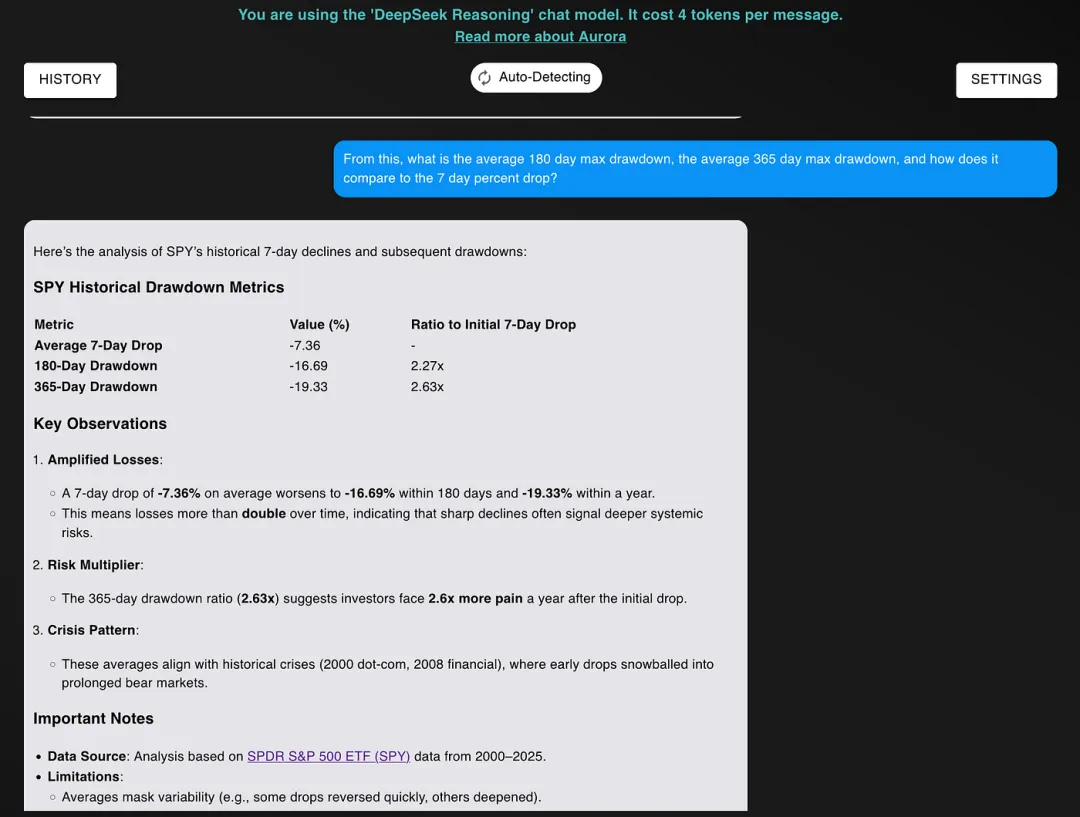
基于此,180 天的平均最大回撤是多少?365 天的平均最大回撤是多少?它们与 7 天的跌幅相比如何?
R1 响应如下:
O1 响应如下:
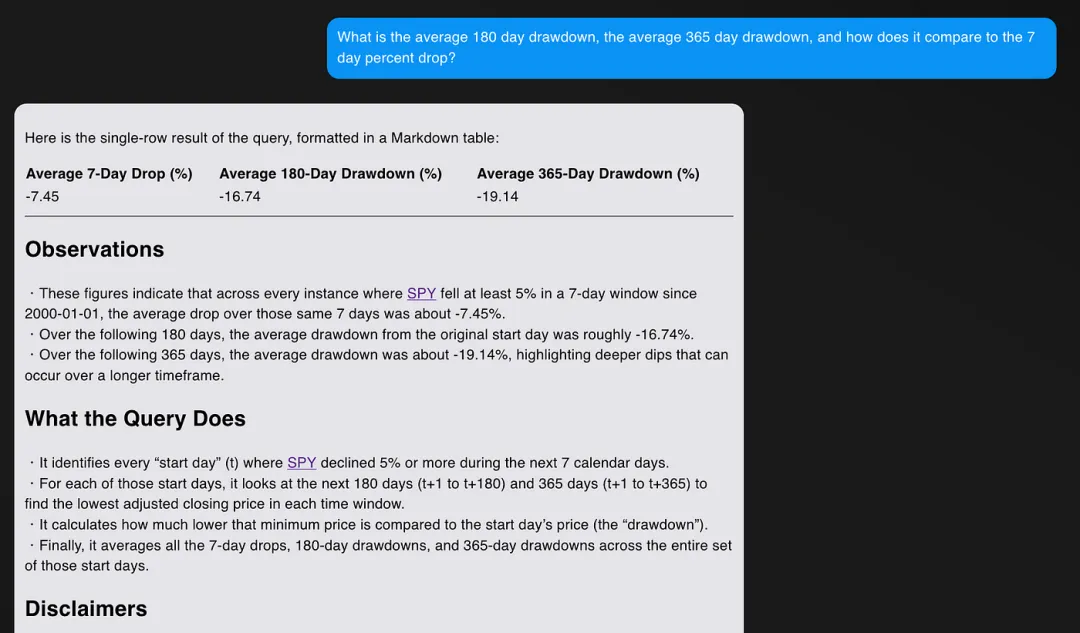
在这个例子中,R1 的回答实际上更好!它通过在回答中包含比率,回答了“与 7 天跌幅相比如何”的问题。
除此之外,两者的回答几乎完全相同。
继续下一个问题
180 天的平均回报是多少?365 天的平均回报是多少?它们与 7 天的跌幅相比如何?
上图是 R1 的回答,下图是 O1 的回答
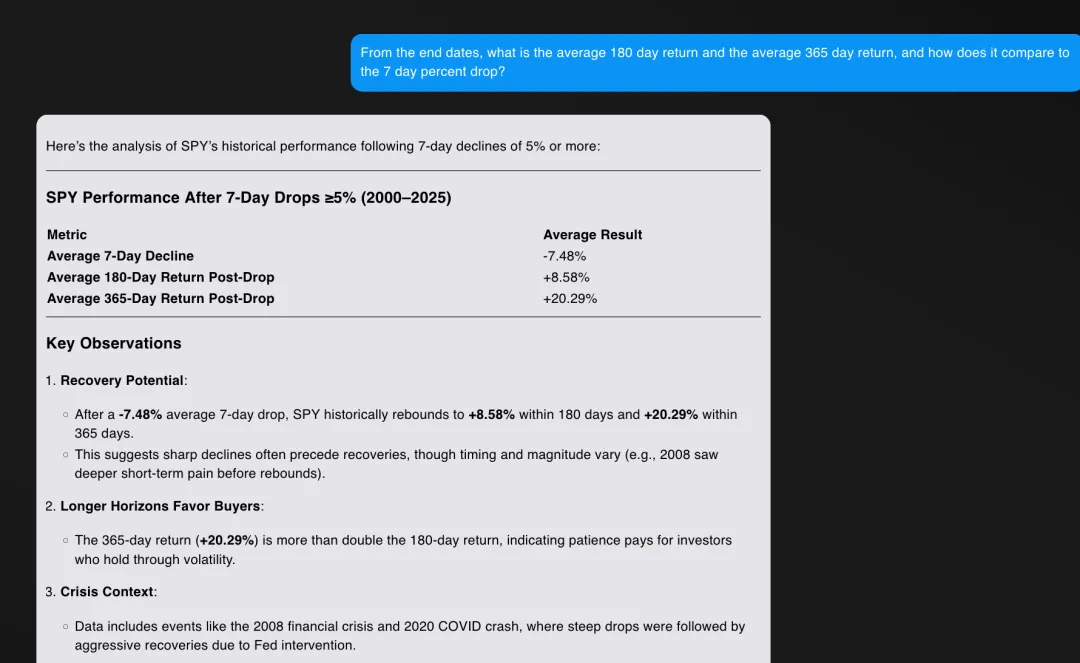
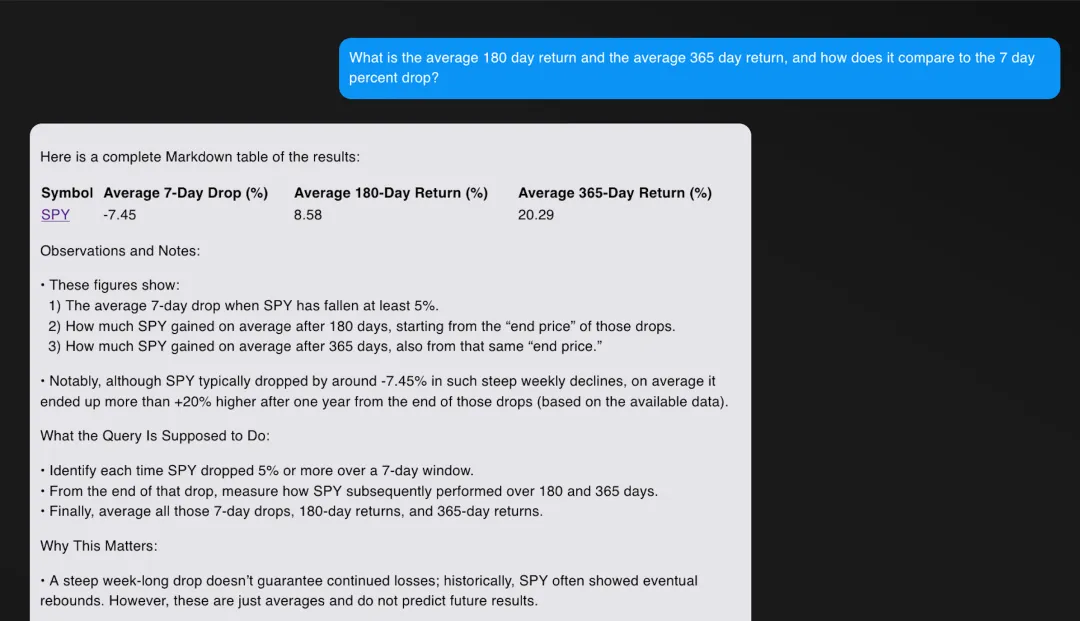
在这种情况下,结果几乎完全相同。R1 的格式稍微好一些,但这完全是主观的。
真正的考验是看 R1 能否在一个完全不同的任务中表现出色——创建自动化交易策略。
使用 R1 和 O1 创建算法的交易策略
要创建一个交易策略,我们本质上是在要求模型生成一个“投资组合”的配置。
创建这个配置涉及多个步骤:
我们创建“投资组合”,包括名称、初始值和交易策略的描述。
根据这个描述,我们创建“策略”配置。这个配置包括一个操作和描述何时执行该操作的“条件”。
根据这个描述,我们创建“条件”配置,它可以被解释为算法交易的条件。
这种将一个提示的输出作为另一个提示的输入的过程称为“提示链”(Prompt Chaining)。
具体操作如下……我们只需向模型提出以下问题:
创建一个初始资金为 10,000 美元的投资组合,并包含以下策略:
如果我们的 SPXL 持仓少于 500 美元,则用 50% 的可用资金买入 SPXL。
如果我们过去 10,000 天内未卖出 SPXL 且 SPXL 持仓盈利 10% 或以上,则卖出 20% 的投资组合价值的 SPXL。
如果 SPXL 股价比我们上次卖出时上涨了 10%,则卖出 20% 的投资组合价值的 SPXL。
如果我们的 SPXL 持仓下跌 12% 或更多,则用 40% 的可用资金买入 SPXL。
与 O1 一样,模型正确响应,并在第一次尝试中就生成了一个高盈利的算法交易策略。
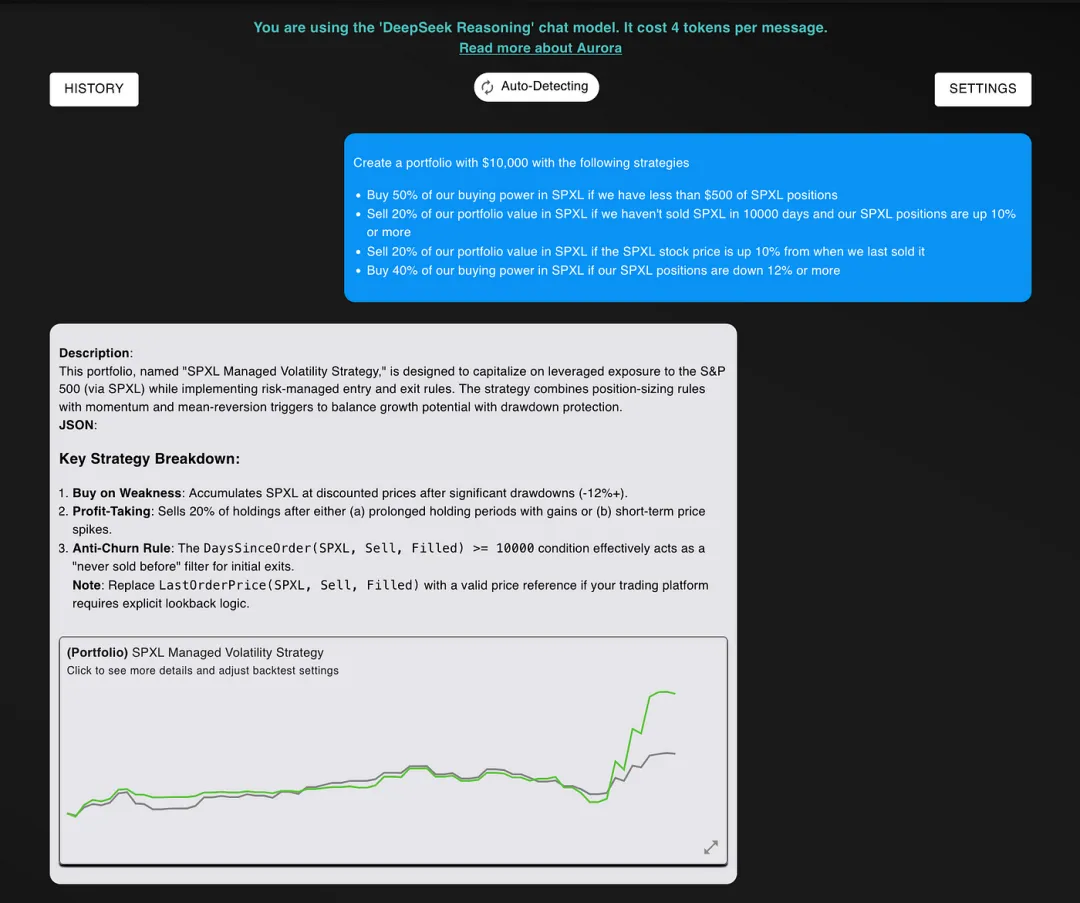
与标普 500 相比,这一策略表现非常出色。它的收益是市场的两倍,夏普比率更高,索提诺比率也更高,同时最大回撤与市场相似。
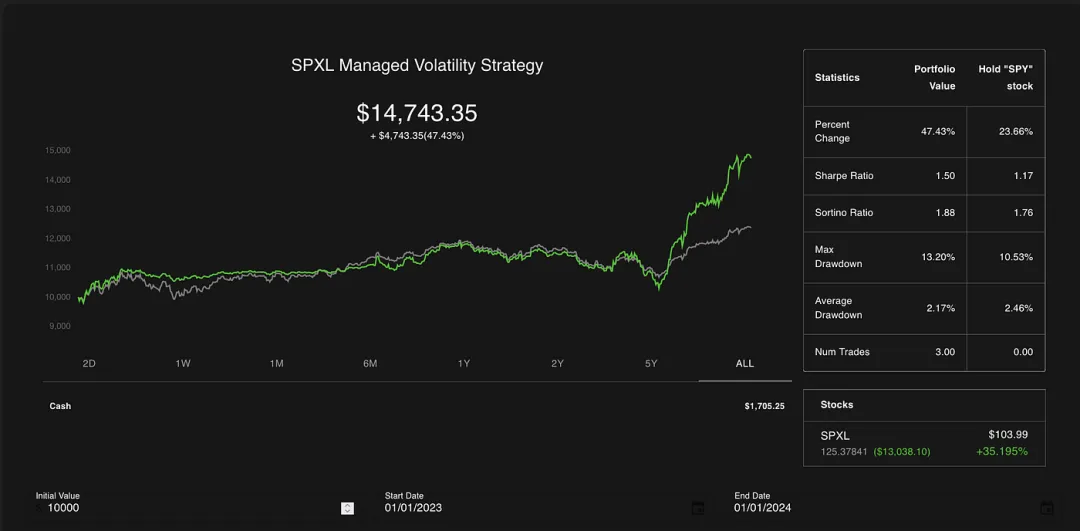
太不可思议了!
本分析的注意事项:该模型并非完美
尽管能够完美生成准确的查询和 JSON 配置,但该模型确实存在一些缺点。
首先,在查看该模型的日志时,我注意到它有时会生成无效的 SQL 查询。
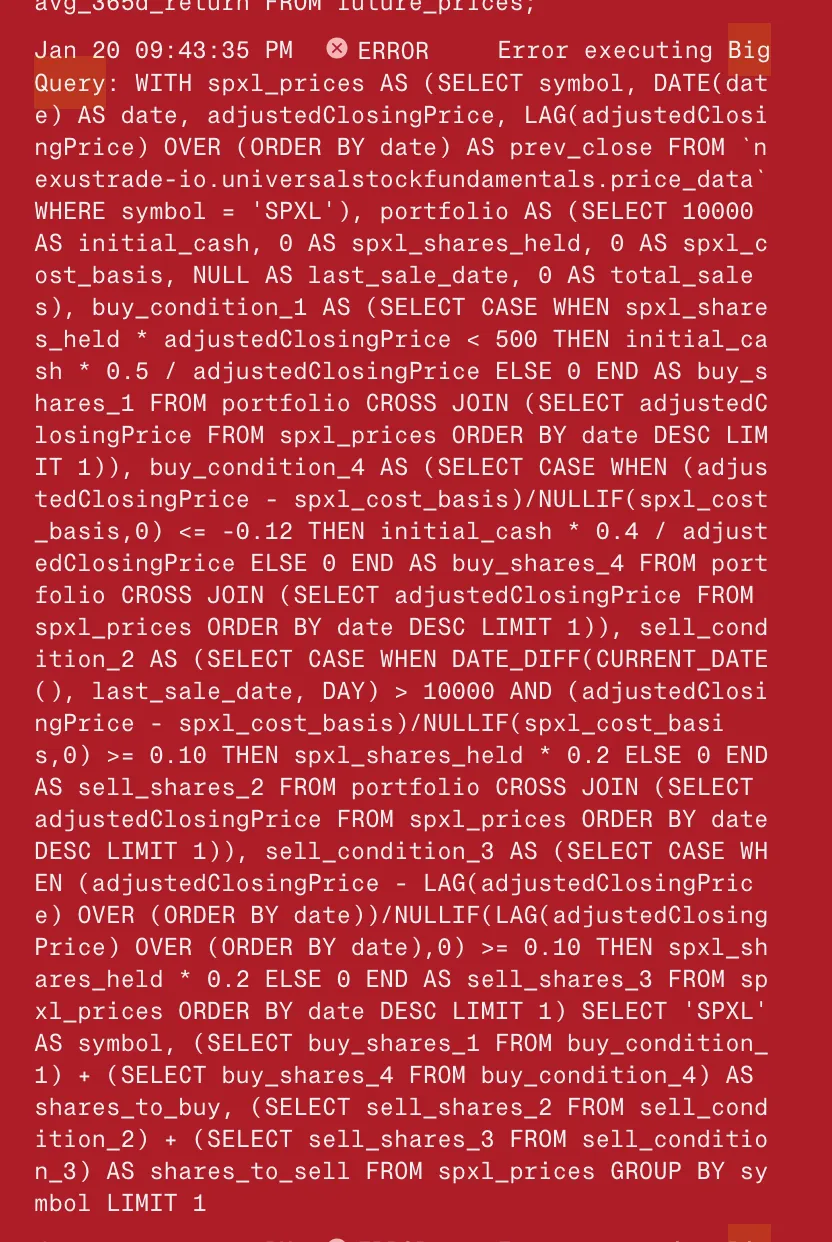
然而,由于我的平台具有自我纠正逻辑,它会自动重试那些没有意义或无效的查询,因此这并不是一个大问题,因为它往往会自行纠正。
除此之外,有一次模型确实超时了,没有对我提出的问题给出有效响应。

我不得不重新提问,而第二次它正确地回答了问题。
我并不是说其他模型(如 O1)没有这些问题;我只是没有注意到它们。但以 2% 的价格,你实际上可以用 R1 发送 50 倍的消息来获得类似的答案。
因此,这些小问题对我来说完全不是问题。这个模型带来的价值令人惊叹,它让强大的 AI 技术对每个人都更加触手可及。有了这个模型,我每月 200 美元的 ChatGPT Pro 订阅费几乎显得浪费。这足以说明问题。
总结
对于 OpenAI 的推理模型,我并不是一见钟情。我发现它慢得离谱且非常昂贵。直到我开始使用它,并看到它在金融分析和算法交易中的惊人表现时,我才爱上了它。
而对于 DeepSeek 的 R1,我几乎是一见钟情。这个词虽然被过度使用,但在这里,它确实是革命性的。
因为它们是开源的,它们现在赋予了数百万开发者在其模型基础上构建、修改和改进的能力,这将进一步降低成本,并迫使 OpenAI 拿出更具竞争力的产品。
因为它们如此便宜,我可以为我的算法交易平台的所有用户启用该模型,无论你是否是付费用户。
事实上,这个模型既便宜又强大,以至于我将所有用户的默认模型切换为它。由于它仅比 OpenAI 的 4o-mini(他们最便宜的模型,也是我之前的默认模型)贵四倍,我实在找不到不这么做的理由。
有了这个模型,AI 已经变得对每个人都触手可及。OpenAI、Anthropic 和 Google 将面临巨大的挑战。如果一个在更便宜的 GPU 上训练的、规模更小的开源模型能够超越这些数十亿(甚至万亿)美元市值的科技巨头,那么除非他们手中有像“镜之力”这样的陷阱卡,否则他们绝对无法生存。
而整个世界都将从他们的衰落中受益。